nodejs 웹크롤링
노드 JS 웹 크롤링 예제입니다.
토이 프로젝트로 뭘 만들어볼까 고민하던 중에 스트리밍 서비스를 만들어보자!! 생각하고 나름 계획을 짜는 중에
우선 프론트에 쓸 사진들을 다운로드해야겠군...이라 생각하며 크롤러를 만들게 되었습니다.
사진은 https://pedia.watcha.com/ko-KR/
왓챠피디아 - 영화, 책, TV 프로그램 추천 및 평가 서비스
5억 개의 평가를 기반으로 나에게 딱 맞는 영화, 드라마, 책을 추천받으세요.
pedia.watcha.com
이곳에 있는 것으로 사용했습니다. 문제 되면 내리겠습니다.
우선 크롤링을 하기 이전에 해당 사이트의 html 배치를 먼저 봐야 합니다.
홈페이지에 들어가서 개발자 모드를 켜주세요.
이러한 화면이 나옵니다.
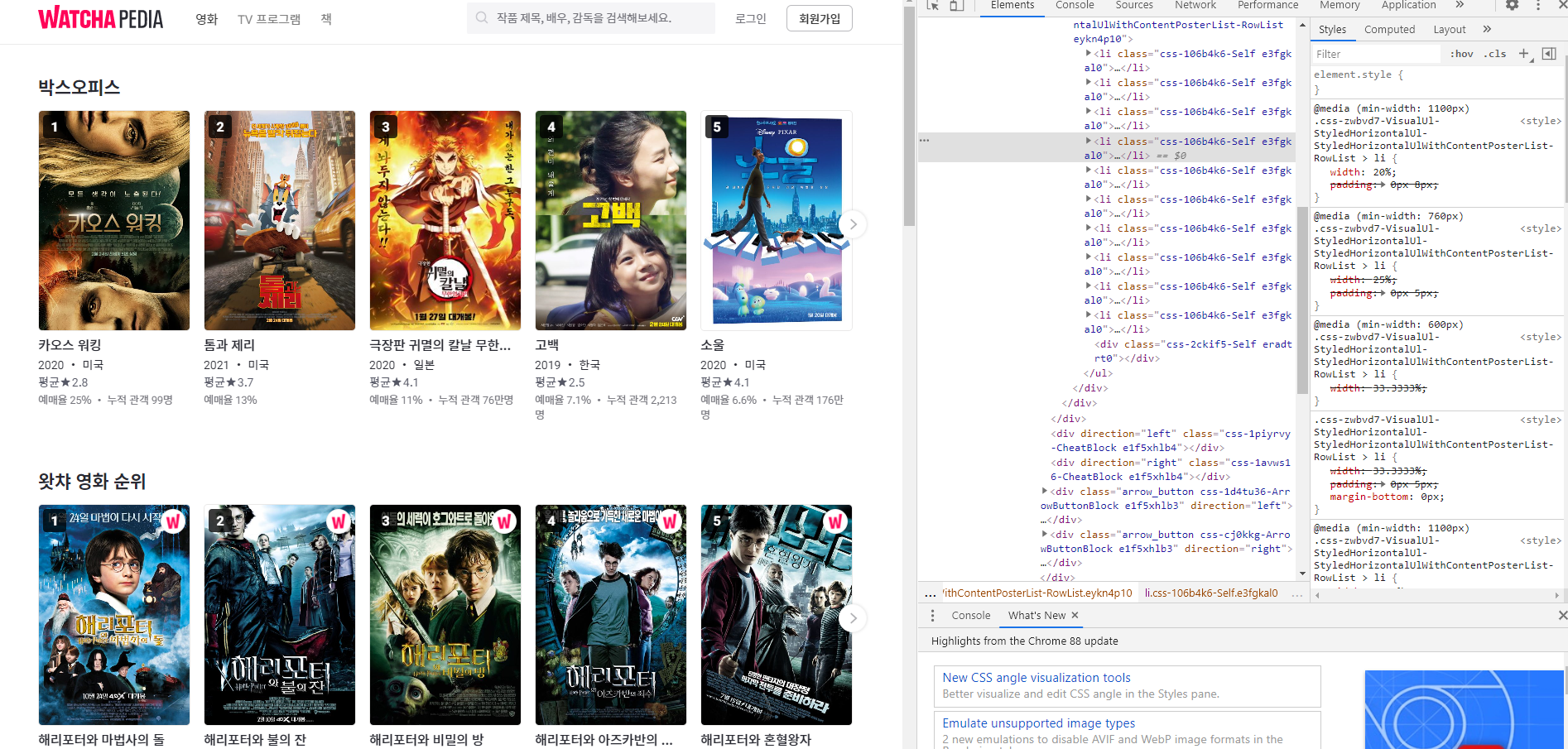
사진이 잘 보이는진 모르겠지만 li 태그 클래스 이름으로 "css-106b4k6-Self e3fgkal0" 이렇게 되어 있습니다.
e3fgkal0 요 친구를 사용해서 크롤링하도록 하겠습니다.
노드js는 설치는
Node.js
Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine.
nodejs.org
들어가셔서 LTS버전으로 설치하면 됩니다.
릴리즈 버전으로요.
npm init -y
npm i axios cheerio
차례대로 입력해주세요.
axios는 http 통신 라이브러리이고
cheerio는 nodejs에서 dom 조작을 가능하게 해주는 라이브러리라고 생각하시면 됩니다. 마치 제이쿼리 셀렉터 같아요.
index.js를 생성하고 패키지를 불러줍니다.
const axios = require("axios");
const cheerio = require("cheerio");
(async () => {
const { data } = await axios.get("https://pedia.watcha.com/ko-KR/");
const $ = cheerio.load(data);
console.log($);
})();이렇게 작성하시고 node ./index.js 하시면 아마 어마어마한 문자열들이 나올 겁니다 좀 더 정확하게는 html을 가져온다고 생각하시면 됩니다.
여기에서 이미지를 가지고 있는 박스들을 가져옵니다.
const parentDiv = $(".e3fgkal0").toArray();그리고 가져온 박스들에서 정보를 뽑습니다.
parentDiv.map(el => {
(async () => {
const movieTitle = $(el).find('a').attr('title');
const movieImgSrc = $(el).find('img').attr('src');
})();
});
이렇게까지 하고 로그를 찍어보세요.

제목과 src가 잘 나오나요
이제 이 정보를 가지고 폴더에 다운을 받아줍니다.
저는 간단하게 images라는 폴더를 하나 생성했습니다.
fs와 path를 불러와주세요.
const fs = require('fs');
const path = require('path');try {
const imgResult = await axios.get(movieImgSrc, {
responseType: 'arraybuffer'
});
fs.writeFileSync(`${path.resolve('imgaes')}/${movieTitle.replace(':', '\-')}.jpg`, imgResult.data);
} catch (error) {
console.log(error)
}여기까지만 해도 완성입니다.
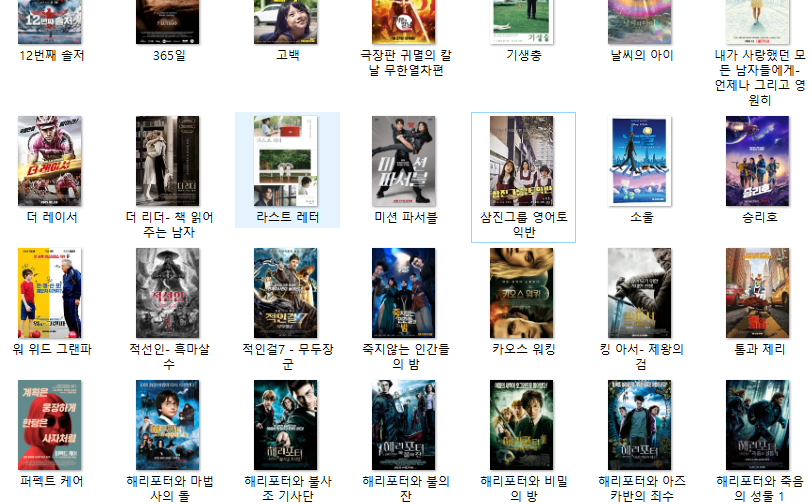
이렇게 하면 폴더에 이미지들이 잘 다운된 걸 확인하실 수 있습니다.
저는 추가로 src에 들어있는 문자 끝부분 타입을 보고 구분해서 이름을 수정하겠습니다.
const imageTypes = ['jpg', 'png'];
imageTypes.map(imgeType => movieImgSrc.indexOf(imgeType))
let imageType = false;
for (let i = 0; i < imageTypes.length; i++) {
if (movieImgSrc.toLowerCase().indexOf(imageTypes[i]) >= 0) {
imageType = imageTypes[i];
break;
}
}이렇게 하면 원본 그대로의 파일 타입을 가지도록 할 수 있습니다.
최종 코드입니다.
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require('fs');
const path = require('path');
(async () => {
const { data } = await axios.get("https://pedia.watcha.com/ko-KR/");
const $ = cheerio.load(data);
const parentDiv = $(".e3fgkal0").toArray();
parentDiv.map(el => {
(async () => {
const movieTitle = $(el).find('a').attr('title');
const movieImgSrc = $(el).find('img').attr('src');
const imageTypes = ['jpg', 'png'];
imageTypes.map(imgeType => movieImgSrc.indexOf(imgeType))
let imageType = false;
for (let i = 0; i < imageTypes.length; i++) {
if (movieImgSrc.toLowerCase().indexOf(imageTypes[i]) >= 0) {
imageType = imageTypes[i];
break;
}
}
try {
const imgResult = await axios.get(movieImgSrc, {
responseType: 'arraybuffer'
});
fs.writeFileSync(`${path.resolve('imgaes')}/${movieTitle.replace(':', '\-')}.${imageType}`, imgResult.data);
} catch (error) {
console.log(error)
}
})();
});
})();
---------------------------------여기까지가 이미지 크롤링입니다.-------------------------------------
하다 보니 재밌어서 하나 더 응용해서 로또 번호 크롤링해봤습니다.
패키지는 동일하니 작성했던 코드를 주석하고 해 보세요.
이번에 가져올 데이터는 네이버입니다.
axios.get("https://search.naver.com/search.naver", {
params: {
sm: 'tab_drt',
where: 'nexearch',
query: `951회로또`
}
})실제 네이버로 검색했을 때 주소
search.naver.com/search.naver?sm=tab_drt&where=nexearch&query=951회로또
951회로또 : 네이버 통합검색
'951회로또'의 네이버 통합검색 결과입니다.
search.naver.com
이런 식입니다. 이걸 제가 일일이 검색 안 하고 프로그램이 대신 데이터를 가져와줄 겁니다.
아까와 비슷하게 우선 html의 구조를 먼저 파악해줍니다.
아래 이미지처럼 lottoWrap이 검색해서 나온 번호들의 부모 요소입니다.
그 아래 num_box > .num을 가져오는데 배열로 변환해서 가져옵니다.
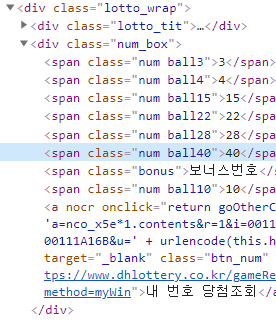
const $ = cheerio.load(data);
const lottoWrap = $("#_lotto");
const children = lottoWrap.find('.num_box').find('.num').toArray();
console.log(children.map((el) => $(el).text()));코드를 실행해보면 로또 번호들이 잘 나오나요?

하나의 결과가 잘 나오는 걸 확인했으니 반복문을 통해 여러 회차를 가져오도록 하겠습니다.
그리고 파일 관리가 쉽게 JSON 형태로 저장하겠습니다. 프리터로 정리 개꿀...
저는 lottos라는 폴더를 생성했습니다.
let lastLotto = 951;
const lottoInfomation = {};
for (let i = 600; i <= lastLotto; i++) {
axios.get("https://search.naver.com/search.naver", {
params: {
sm: 'tab_drt',
where: 'nexearch',
query: `${i}회로또`
}
}).then(({ data }) => {
const $ = cheerio.load(data);
const lottoWrap = $("#_lotto");
const children = lottoWrap.find('.num_box').find('.num').toArray();
lottoInfomation[i] = children.map((el) => $(el).text());
if (Object.keys(lottoInfomation).length > lastLotto - 600) {
fs.writeFileSync(`${path.resolve('lottos')}/lotto.json`, JSON.stringify(lottoInfomation));
}
})
}그리고 파일을 저장할 때 원하시는 키를 넣으시면 됩니다. 저 같은 경우에는 해당 회차를 키 값으로 만들었습니다.
lottoInfomation[i] = children.map((el) => $(el).text());
i 부분을 원하시는 키로 바꾸시면 됩니다.
여기까지 잘 따라오셨다면 600회 차부터 951회 차까지의 당첨번호 데이터를 수집하게 되었습니다.
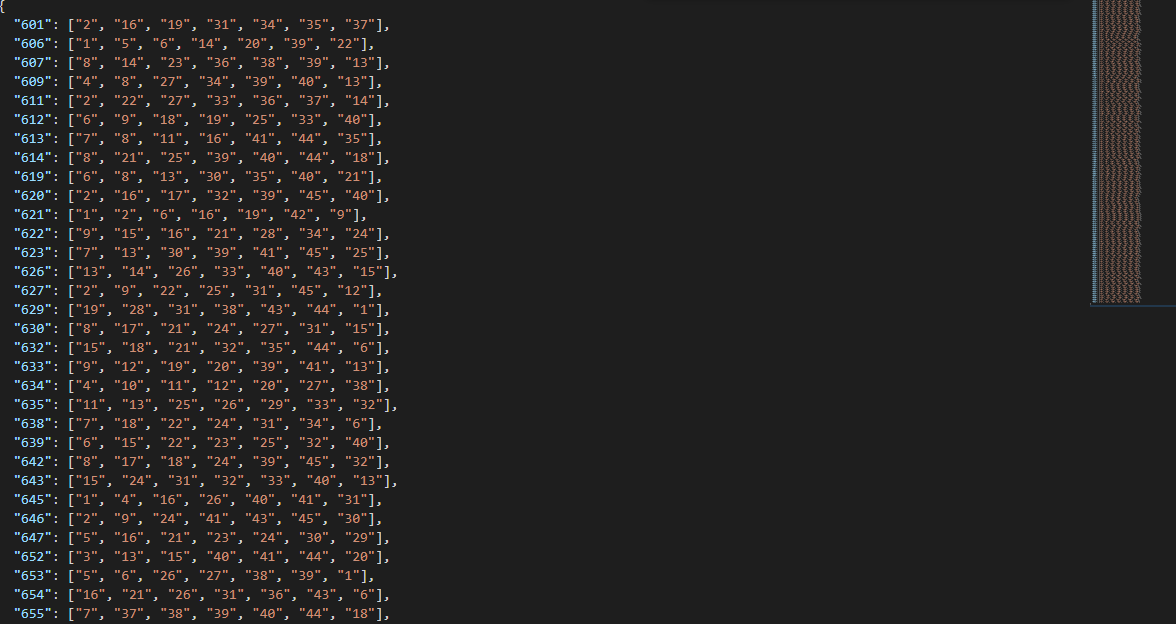
직접 손으로 검색하면 351번을 쳐야 합니다.
공백 제거하고 코드 20줄로 이 모든 일을 해냈습니다. 개꿀~
잘 응용해보시길 ~